
這一次,鋼鐵俠的Javis要跑到設備上
行至2024,云端大模型還未分出勝負,端側模型早已硝煙四起。
去年上半年,谷歌以可在移動設備上離線運行的PaLM2輕量級選手“壁虎”打響了端側模型第一槍,到了年底,端側模型時代的大幕就被緩緩拉起。
法國創企Mistral AI率先發布Mixtral 8x7B模型,微軟更是半年時間加速跑,從27億參數的Phi-2到SLM(小語言模型)Phi-3系列,以“便宜得多,但響應能力接近比它大10倍的模型”強調高性價比。
Google攜帶Gemma模型向Meta的Llama-2大模型發起挑戰,蘋果也以“小模型”家族宣告離“讓人工智能在蘋果設備上本地運行”目標更近一步。
而大洋彼岸的另一側,在中國上海張江,也有這么一家通用大模型廠商,駛上了端側模型的快車道,以類腦分區激活的工作機制、改進反向傳播算法逐步實現“同步學習”,并在走通多模態上率先“卷”入。
這,就是巖芯數智CEO劉凡平帶隊的RockAI。
Yan 1.2跑通樹莓派,“為設備而生”水到渠成
事實上,今年1月,RockAI發布的國內首個非Attention機制的通用自然語言大模型——Yan1.0模型,就標志走向設備端的第一步。
當時這一模型100%支持私有化部署應用,不經裁剪和壓縮即可在主流消費級CPU等端側設備上無損運行,在研究人員現場對Yan 1.0模型在Mac筆記本上的運行推理展示中,劉凡平也畫出了接下來將在更加便攜的設備或終端中進行無損部署的藍圖。
而現在,隨著Yan 1.0邁入1.2階段,“在樹莓派上率先跑通”把其在更低端設備的無損適配從預期變為了現實。
圖為Yan架構模型在樹莓派上運行
樹莓派系列作為全球最為知名的袖珍型小巧卻又性能強大的微型電腦,可廣泛應用于物聯網、工業自動化、智慧農業、新能源、智能家居等場景及設備,譬如門禁、機器人等終端,但它雖具備所有PC的基本功能,卻是算力最低的設備代表。
同時,樹莓派大部分情況沒有聯網,這就意味著,跑通樹莓派,等同于打開了低算力設備端的大門以及不聯網的多場景應用。
不過,機遇之大,挑戰亦不小,不少大模型玩家都屈身于“有損壓縮”。
就連4月網友發現能在樹莓派5以每秒1.89個token的速度運行,支持8K上下文窗口的Llama3 8B ,也是采用把模型量化裁剪后壓到極致的方式。
而這就如同把平鋪的紙揉小后放入,會導致紙張有褶皺般,讓多模態下的性能損失無法恢復到原有狀態去進行模型訓練,同時也伴隨著卡住不動、死機等不確定情況發生。
此時,原生無損放入的重要性就凸顯,而這正是RockAI基于底層技術做“破壞式”創新的優勢所在。
不同于傳統Transformer模型自帶算力消耗和幻覺等問題,Yan架構為低算力設備運行而生,1.0版就以百億級參數媲美千億參數大模型的性能效果,以記憶能力提升3倍、訓練效率提升7倍的同時,實現推理吞吐量的5倍提升,實現云端運行的高性價比。
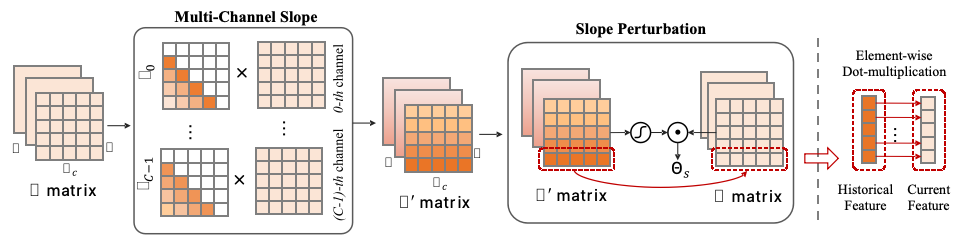
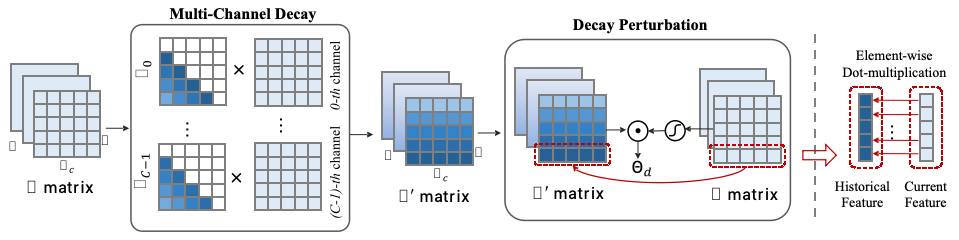
圖為Yan架構模型的關鍵模塊MCSD Block,引自Yan架構論文: 《MCSD: An Efficient Language Model with Diverse Fusion》
對比數據表明,在單張4090 24G顯卡上,當模型輸出token的長度超出2600時,Transformer的模型會出現顯存不足,而Yan模型的顯存使用始終穩定在14G左右,理論上能夠實現無限長度的推理。
再到讓通用大模型去兼容更多的設備,實現更多個性化的設備端應用,則讓RockAI在同模型架構下,可水到渠成地“為設備而生”。
那么,對于樹莓派這一門檻,RockAI是如何破局的呢?答案就在技術創新上。
自創業之初,劉凡平就一直在思考“大模型動輒上萬億的token訓練是否真的必要”,以人類大腦幾十億的訓練量來看,他判斷,數據、算力并不是最終的瓶頸,架構、算法才是重要的影響因素。
故而在跑通樹莓派的路上,基于全新自研的Yan架構,RockAI在實驗室對人工神經網絡最底層的反向傳播算法進行挑戰,尋找反向傳播的更優解嘗試。
而在算法側,RockAI更是在上半年率先有所突破,在人腦神經元分區激活的啟發下,實現了類腦分區激活的工作機制。
如同人開車跟寫字會分別激活腦部的視覺區域和閱讀區域一般,Yan 1.2也不再需要全量的參數去訓練,會根據學習的類型和知識的范圍來決定只調整哪部分神經元,而這種分區的激活方式不僅可以減少數據訓練量,同時也能有效發揮多模態的潛力,該算法被RockAI稱作基于仿生神經元驅動的選擇算法。
數據表明,人腦的神經元大概是800-1000億,功耗大概是20-30瓦,而一臺GPU算力服務器功耗能到2000瓦,這就意味著主流大模型的全參數激活,本身就是不必要的大功耗浪費。
在今年3月類腦分區激活的工作機制實現后,甚至10億級參數的Yan模型通過改進在0壓縮和0裁剪的情況下在一臺7年前生產的Mac筆記本的CPU上跑通。
2個月后,“原生無損”跑通樹莓派的故事便在RockAI如期而至。
劍指“同步學習”,Yan模型也能千人千面
跑通樹莓派,是RockAI走通低端設備上的里程碑,同時也預示著距離其“同步學習”概念落地更近了一步。
眾所周知,Transformer大模型帶來一種開發范式——先通過預訓練讓大模型具備一定的基本能力,然后在下游任務中通過微調對齊,激發模型舉一反三的能力。
但這樣的云端大模型雖好,在實踐中卻有著不能實時改進和學習的問題。
Transformer架構在大參數大數據的情況下,想在預訓練完成之后再大規模的反向更新代價極其大的,尤其對算力要求非常高,更別提返到原廠去重新訓練的時間和經濟成本。
也就導致在嚴謹內容場景下,一旦有內容和評價發生較大轉變,Transformer大模型學徒們往往要1-2個月去把數據清掉后,再重新訓練后進行提交,客戶一般很難接受。
這些toB實踐中的真實反饋,讓劉凡平意識到客戶對模型立即更新的需求,這要求模型不僅具備實時學習的能力,同時學習之后不能胡說八道。
懷揣著“機器能否具有像人一樣實時學習的能力”的思考,以及跟著客戶真實需求走的大方向指引,同步學習這一解法,在RockAI逐步清晰。
相比較泛機器學習領域的實時學習和在線學習、增量學習等概念,劉凡平認為RockAI首創的同步學習概念差異性在于,做知識更新和學習時在模型層面訓練和推理同步進行,以期實時、有效且持續性地提升大模型的智能智力,應對各類個性化場景中出現的問題。
而要理解快速更新的問題,涉及到現在神經網絡的底層原理,本質上神經網絡的訓練是前向傳播和反向傳播的過程。
就如同你正在玩一個猜數字游戲,你需要猜出一個1到100之間的隨機數。在開始時,你沒有關于這個數字的任何信息,所以你的第一次猜測可能是基于直覺或是隨便選了一個數,比如50。這就好比是神經網絡中的前向傳播——在沒有任何歷史數據的情況下,根據當前的參數(權重和偏置)進行一次預測。
當你猜測了50后,游戲會告訴你這個數字“太大”或“太小”。如果你聽到“太大”,那么下一次猜測時,你會選擇小于50的一個數;如果得到反饋是“太小”,你則會選擇一個大于50的數。
這就類似于反向傳播對參數的調節過程。只要模型調整足夠快、代價足夠小,就能更快達到預期,實現從感知到認知再到決策這一循環的加速,對現有知識體系進行快速更新。
為此,RockAI給出的同步學習解法落在,不斷嘗試尋找反向傳播的更優解,試圖能更低代價更新神經網絡,同時以模型分區激活降低功耗和實現部分更新,從而使得大模型可以給到客戶后持續成長,像人類學習一樣建立自己獨有的知識體系。
在劉凡平的設想中,通過同步學習,Yan模型部署到各類設備后,會更像貼身伴侶,伴隨著個人的習慣去進行學習和服務,越來越具備個性化的價值,讓手機、電腦,甚至電視、音響等智能家居都能個性化適配到每個人,最終形成可交互的多樣性智能生態。
如此說來,那就是每個人在設備上都會找到自己的Javis(鋼鐵俠的AI管家)。
奔赴2.0,RockAI蓄力C端商業化
把時間線拉長到近半年來看,RockAI的迭代呈現加速度。
3月,類腦分區激活的工作機制實現;5月初,“無損”跑通樹莓派;5月底,全模態部分視覺支持走通。
雖然同步學習仍在實驗室最后驗證階段,仍需要大規模測試,但劉凡平表示,隨著把多模態的視覺、觸覺和聽覺能力補齊,Yan 2.0也最快于今年年底面世。
“屆時,全模態支持+實時人機交互+同步學習的落地,Yan 2.0的出現或將補齊具身智能的大腦短板。”
技術端的加速,背后是團隊“吃苦”換來的。劉凡平坦言,干的都是其他廠商“不愿干”,也可能“干不了”的活。
算法端,RockAI兵分兩路,一部分去做基礎算法和模型架構的創新升級,在1.2基礎上朝著2.0進發;另一部分則廣泛收集客戶反饋,通過不斷調整去貼近商業化落地。
劉凡平認為只有最大程度獲取來自于外界和客戶的感知和需求,才能避免閉門造車與用戶的距離太遠,逐漸形成明確和清晰的商業化路線。
而算法創新外,要實現Yan 2.0落地即商業化的未來,工程團隊也在做大量的標準化的“周邊”補齊,包括基礎設施、系統、交付等方方面面,解決方案團隊更是從率先商業化的B端客戶“掃”到設備廠商,邊進化邊驗證降本增效和市場認可度。
劉凡平也帶著團隊奔走于上海、深圳、杭州等地,與中科曙光、華為昇騰、壁仞科技、廣電五舟等眾多硬件和芯片廠商建立了溝通,在端側模型的適配工作上,劉凡平能感受到設備端“積極提供測試機”的熱情,特別是樹莓派跑通后給到了話語權,機器人廠商們都開始競相走訪。
而這些前置工作,都為接下來Yan2.0落地合適場景可能試產1-2萬臺的標品規模化做足“迅速跟上”的周期準備。
就端側模型來說,劉凡平認為對于設備廠商而言,是類似Windows操作系統般的存在。現階段可能是系統在適配各種硬件,到了設備廠商深入了解模型的人工智能能力后,就需要設備反向兼容操作系統,而兩者合力,是社會分工生產力變化的一個必然趨勢。
“站在toC智能化甚至具身智能的大話題下,端側模型需要結合實際載體(即硬件)去做適配研究和迭代改進,才能逐步形成標準化的類Windows操作系統,既可以裝在個人電腦也可以適配穿戴設備,而不同的身體就會需要不同的腦子,我們所構想的通用人工智能,是在諸如智能手機、機器人以及其他多樣化設備上展現出的非凡適應力與高度個性化的交互能力。”
作為一家從B端商業化驗證過“模”力的企業,劉凡平坦言,當前商業化重心部署到C端設備,是低算力的基因使然,亦是AI與本地設備結合的個性化趨勢必然,也是跳出B端商業化內卷,搶占C端藍海市場的先機。
在RockAI的辦公室內,擺滿了眾多的各類硬件設備,劉凡平笑道,還有大量的適配和兼容工作需要完成,而一旁來自深圳各個廠商的機器人也在等待適配他們的“大腦”。
從Yan 1.0到Yan 1.2,RockAI花了4個月時間,再到2.0,想必也不會太久。

 獵云網
獵云網


 融中財經
融中財經





