
遭斯坦福AI團隊抄襲?面壁智能CEO李大海最新回應來了
“一方面感慨這也是一種受到國際團隊認可的方式,另一方面也呼吁大家共建開放、合作、有信任的社區環境。”
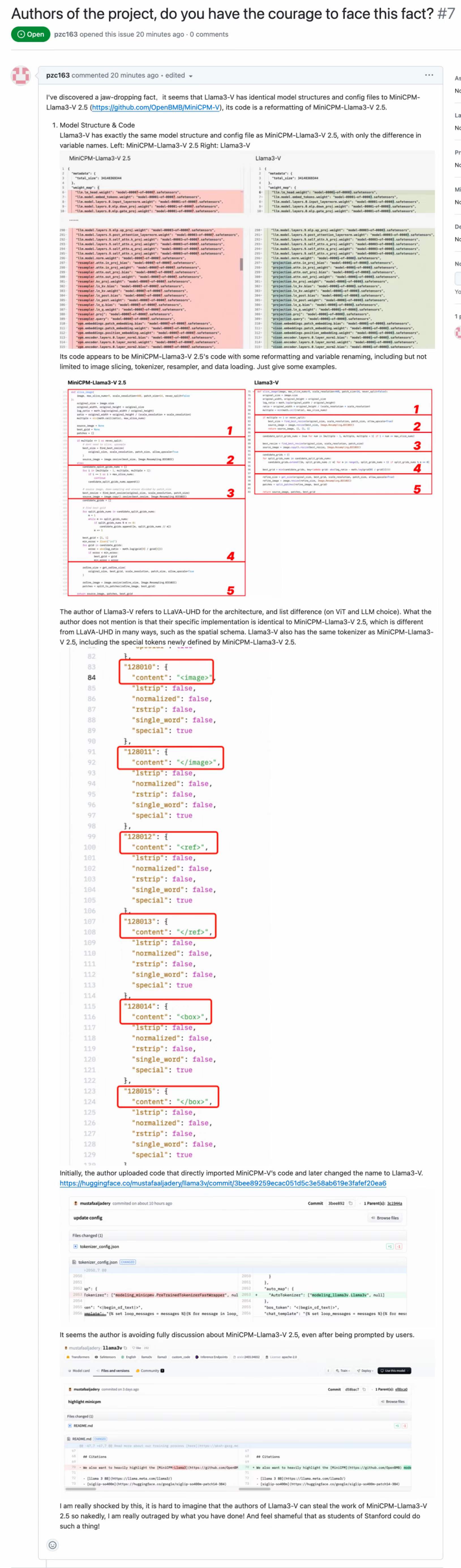
大模型領域,出現罕見一幕!
近日,斯坦福某AI團隊(下稱:斯坦福團隊)被曝抄襲面壁智能開源成果,有“套殼”嫌疑:模型結構和代碼“展現出驚人的相似度”。
針對此事,知乎CTO、面壁智能CEO李大海表示:我們對這件事深表遺憾!一方面感慨這也是一種受到國際團隊認可的方式,另一方面也呼吁大家共建開放、合作、有信任的社區環境。

來源:朋友圈截圖
對于“抄襲”行為本身,面壁智能方面也給出了補充介紹。
李大海介紹到,“經過團隊核實,除了社區網友列出的證據外,我們還發現 Llama3V展現出和小鋼炮一樣的清華簡識別能力,連做錯的樣例都一模一樣,而這一訓練數據尚未對外公開。這項工作是團隊同學耗時數個月,從卷帙浩繁的清華簡中一個字一個字掃描下來,并逐一進行數據標注,融合進模型中的。更加tricky的是,兩個模型在高斯擾動驗證后,在正確和錯誤表現方面都高度相似。”
來源:朋友圈截圖

來源:朋友圈截圖
事件始于5月29日,斯坦福團隊發布Llama3V項目,并宣稱500美元即可訓練出一個多模態大模型,效果比肩GPT-4V、Gemini Ultra、Claude Opus等。
憑借著低廉的價格、優秀的團隊背景,上述模型發布的推文在X平臺(推特)獲得了較大關注。
大量關注下,隨即被眼尖的網友發現,Llama3V項目與面壁智能最新發布的多模態模型MiniCPM-Llama3-V 2.5“雷同”。
面對越來越多的抄襲“質疑”,斯坦福團隊也從最初的“狡辯”,變成了“刪庫跑路”。至此,“抄襲”風波漸息。
經歷此事,李大海不無感慨,“?技術創新不易,每一項工作都是團隊夜以繼日的奮斗結果,也是以有限算力對全世界技術進步與創新發展作出的真誠奉獻。我們希望團隊的好工作被更多人關注與認可,但不是以這種方式。”
【本文為合作媒體授權博望財經轉載,文章版權歸原作者及原出處所有。文章系作者個人觀點,不代表博望財經立場,轉載請聯系原作者及原出處獲得授權。有任何疑問都請聯系(聯系(微信公眾號ID:AppleiTree)。免責聲明:本網站所有文章僅作為資訊傳播使用,既不代表任何觀點導向,也不構成任何投資建議。】




